
















Xiaomi выпустила «самую мощную LLM с открытым исходным кодом для программной инженерии» — MiMo-V2-Flash
Xiaomi сообщила о выпуске бесплатной и открытой модели искусственного интеллекта MiMo-V2-Flash. Её отличают высокие мощность, эффективность и скорость — модель хорошо проявляет себя в сценариях с рассуждениями, программированием и работы в качестве ИИ-агента. Это отличный универсальный помощник для повседневных задач, утверждает разработчик.
ИИ-модель MiMo-V2-Flash доступна для пользователей по всему миру на платформе Hugging Face, в инфраструктуре Google Cloud AI Studio, а также на собственной платформе Xiaomi для разработчиков. MiMo-V2-Flash имеет архитектуру «смеси экспертов» — её общий размер составляет 309 млрд параметров, из которых активны только 15 млрд. Ещё один механизм оптимизации — гибридный механизм полного внимания (Global Attention), при котором охватываются все токены контекста, и скользящего окна (Sliding Window Attention), предусматривающего учёт только текущего и соседних с ним токенов. Он реализуется в соотношении 1:5 — если провести параллель, модель при ответе основную часть времени смотрит себе под ноги, но иногда осматривает и всю дорогу целиком. Это позволяет добиться скорости, сравнимой с механизмом скользящего окна, при точности почти как при чистом механизме полного внимания.
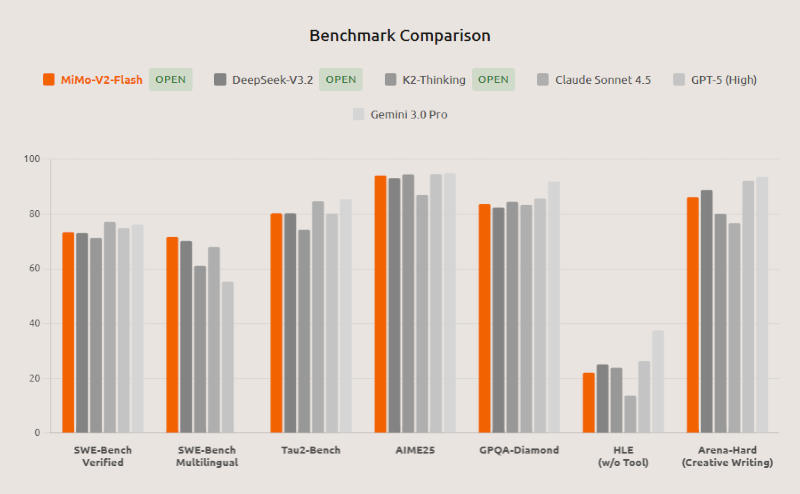
В стандартных тестах SWE-bench Verified и Multilingual, которые помогают оценить способности ИИ к разработке ПО, MiMo-V2-Flash, по утверждению Xiaomi, заняла первое место среди всех открытых моделей и выступила на уровне ведущих мировых моделей с закрытым кодом. В математическом AIME 2025 и междисциплинарном GPQA-Diamond она вошла в число двух лучших открытых моделей в мире. MiMo-V2-Flash поддерживает гибридную схему мышления, позволяя пользователям переключать модель между режимом рассуждения и форматом быстрых ответов. Поддерживается генерация полнофункциональных HTML-страниц в один клик; есть возможность интеграции со сторонними инструментами «вайб-кодинга», в том числе Claude Code, Cursor и Cline; длина контекстного окна составляет 256 тыс. токенов, что позволяет MiMo-V2-Flash выполнять задачи в течение нескольких сотен раундов взаимодействия с агентами и вызова сторонних инструментов.
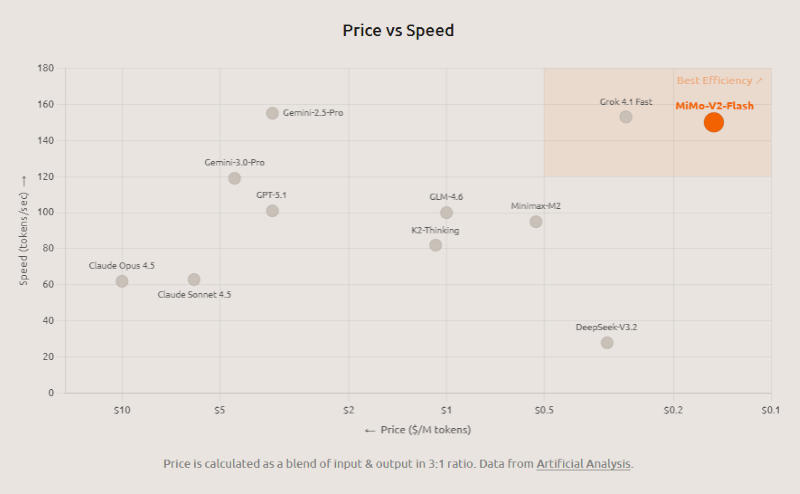
Механизмы оптимизации помогли «разогнать» MiMo-V2-Flash до скорости ответа в 150 токенов в секунду — по субъективным ощущениям они выдаются почти мгновенно. В инфраструктуре Xiaomi при подключении через API стоимость работы с моделью составляет $0,1 за 1 млн входных и $0,3 за 1 млн выходных токенов. Помимо гибридного механизма полного внимания и скользящего окна, разработчик повысил скорость модели, обучив её генерировать по нескольку токенов одновременно (Multi-Token Prediction — MTP): первоначально они генерируются в черновом формате, проверяются и сразу могут направляться в ответ. На практике модель генерирует в среднем от 2,8 до 3,6 токенов параллельно, что помогает ускорить её работу на величину от 2,0 до 2,6 раза.
Ещё одно нововведение в Xiaomi развернули на этапе постобучения MiMo-V2-Flash — парадигму «динамической дистилляции знаний от группы наставников» (Multi-Teacher Online Policy Distillation — MOPD). Это значит, что ответы обучаемой модели оцениваются моделями-наставниками в реальном времени, причём последние дают свои рекомендации не по схеме «правильно или неправильно», а предлагают разбор ошибок. Обучаемая же модель при этом анализирует свои собственные ответы, а не действует в рамках заданных сценариев. Эта схема позволяет использовать всего 2 % вычислительных ресурсов по сравнению с традиционным сценарием обучения с подкреплением при тонкой настройке (SFT/RL). Кроме того, децентрализованная структура MOPD позволяет прошедшему обучение «ученику» впоследствии исполнять роль «наставника» — другими словами, модель непрерывно самосовершенствуется.
По совокупности тестов модель MiMo-V2-Flash демонстрирует результаты, сравнимые с показателями ведущих китайских систем K2 Thinking и DeepSeek V3.2 Thinking; причём в задачах с длинным контекстом нейросеть от Xiaomi превзошла значительно более крупную K2 Thinking, оправдав архитектуру скользящего окна. В тесте SWE-Bench Verified она набрала 73,4 %, обошла все открытые аналоги и выступила почти на уровне OpenAI GPT-5-High; в SWE-Bench Multilingual решила 71,7 % задач, подтвердив статус самой эффективной открытой модели для разработки ПО. В тестах τ²-Bench на работу в качестве отраслевого ИИ-агента она показала результаты в 95,3 баллов для телекоммуникационного направления, 79,5 для розничной торговли и 66,0 для авиакомпаний. В бенчмарке поисковых агентов BrowseComp она набрала 45,4 балла, а с учётом управления контекстом — 58,3. Веса модели, включая MiMo-V2-Flash-Base, доступны на Hugging Face по лицензии MIT, код для инференса (вывода) направлен разработчикам фреймворка SGLang.