
















В интернете появилась система, которая заставит разработчиков ИИ платить за контент

Представлен открытый стандарт лицензирования контента Really Simple Licensing (RSL), который даст медиакомпаниям возможность определять условия оплаты за сбор ботами данных для обучения ИИ. Новый стандарт позволит веб-издателям прямо в файле robots.txt на своих сайтах устанавливать условия использования их произведений. Многие крупные компании, в том числе Reddit, Yahoo, Medium, Quora, IGN и People Inc., уже объявили о поддержке RSL.
Стандарт RSL основан на протоколе robots.txt, который позволял издателям давать инструкции поисковым роботам о том, к каким разделам сайта они могут получить доступ, а к каким — нет. Но вместо того, чтобы просто говорить «да» или «нет» конкретным ботам, сайты теперь могут добавлять условия лицензирования и выплаты роялти в свой файл robots.txt. Они также могут встраивать эти условия в онлайн-книги, видео и обучающие наборы данных, за которые необходимо получить компенсацию.
За стандартом RSL стоит недавно созданная правозащитная организация RSL Collective, возглавляемая Экартом Вальтером (Eckart Walther), соавтором стандарта Really Simple Syndication (RSS) и Дугом Лидсом (Doug Leeds), бывшим генеральным директором IAC Publishing и Ask.com. «Цель — создать новую масштабируемую бизнес-модель для интернета, — сообщил Вальтер. — RSL берёт некоторые из этих ранних идей RSS и создаёт новый уровень для всего интернета, где определяются права лицензирования и права на компенсацию».
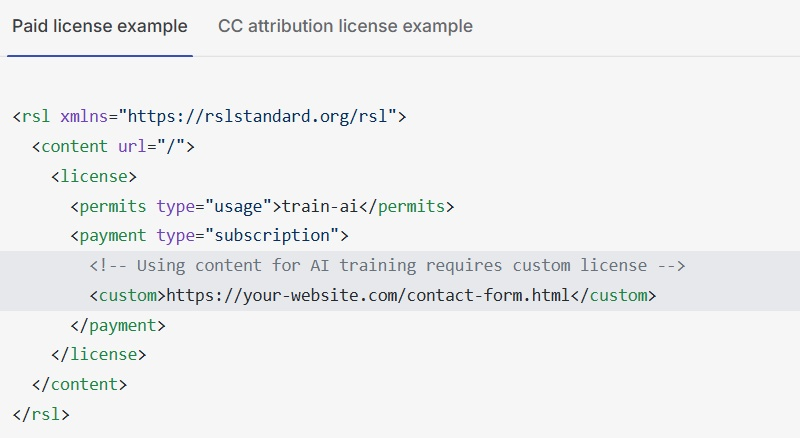
Стандарт RSL поддерживает различные модели лицензирования, включая бесплатные. Владельцы сайтов могут попросить компании, работающие с ИИ, оплатить подписку или назначить плату за каждое сканирование. Они также могут ввести плату за вывод, позволяя сайтам получать компенсацию, когда модель ИИ ссылается на их работу для генерации ответа. Боты, сканирующие сайты для других целей, например, для архивирования или включения в поисковые системы, могут работать в обычном режиме.
Некоторые медиакомпании, включая Vox Media, материнскую компанию The Verge, News Corp, владеющую The Wall Street Journal, и The New York Times, уже заключили лицензионные соглашения с отдельными разработчиками ИИ, такими как OpenAI и Amazon. RSL Collective стремится упростить этот процесс, позволяя любому владельцу или создателю сайта получать оплату за свою работу без заключения множества отдельных соглашений.
Как и в случае со многими другими стандартами, успех RSL зависит от того, насколько его поддержат крупные игроки отрасли. Разработчиков ИИ неоднократно обвиняли в игнорировании файлов robots.txt, и не существует простого способа подсчитать размер платы за вывод без их участия. RSL Collective делает ставку на то, что объединение усилий крупнейших веб-издателей сделает принятие стандарта более привлекательным. «Наша задача — выйти и убедить большую группу людей заявить, что это в ваших интересах. Это эффективно, поскольку вы можете договориться со всеми сразу, и юридически значимо, поскольку, если вы этого не сделаете, вы нарушите все сразу», — говорит Лидс.
Стандарт RSL сам по себе не может блокировать посещение веб-сайта ботами, в отличие от системы «оплаты за сканирование», предлагаемой Cloudflare. RSL Collective в настоящее время работает с сетью доставки контента Fastly, чтобы допускать ботов ИИ на сайты только при согласии с политикой лицензирования. Fastly — это «вышибала у входа в клуб, и они не впустят людей без соответствующего удостоверения личности», — образно пояснил Лидс.

Лидс считает, что RSL Collective также может юридически обеспечивать соблюдение лицензий, что позволит, по его словам, «всем участникам организации коллективных прав участвовать в борьбе с любыми нарушениями» и совместно нести судебные издержки. Он сравнивает RSL с существующими организациями по защите цифровых прав, такими как группа по защите музыкальных прав ASCAP, которая собирает лицензионные сборы и распределяет их между участниками.
Хотя традиционное лицензирование музыки пользуется особенно сильным и устоявшимся правовым прецедентом защиты авторских прав, несанкционированный сбор данных и использование медиафайлов для обучения систем ИИ всё ещё находятся в «серой зоне» правового регулирования. В настоящее время крупные игроки на рынке ИИ выступают ответчиками по судебным искам от Reddit, Getty Images и многих других онлайн-издателей.
«Всегда стоял вопрос о том, соглашаются ли боты на условия, которые они не видят, — поясняют разработчики. — RSL меняет это принципиально, информируя поисковые роботы об условиях ещё до того, как они зайдут на сайт». Они рассчитывают, что новый стандарт лицензирования контента сможет создать интуитивно понятный способ навигации по лицензированию обучения ИИ.